


Many web scrapers in Python encounter the “urllib.error.HTTPError: HTTP Error 403: Forbidden” error when they use the urllib module. If you are one of them, then keep reading because we’ll explain how to resolve the urllib.error.HTTPError: HTTP Error 403: Forbidden in this article.
In contrast to the requests library, which is not a built-in library, the urllib module can send an HTTP request to a website. We will go through the causes and solutions to “urllib.error.HTTPError: HTTP Error 403: Forbidden” in the subsequent article.
In addition to that, we will discuss in detail how to resolve the “urllib.error.HTTPError: HTTP Error 403: Forbidden” error, generated when the request classes find a forbidden resource. So before we dive deep into the article, we first go through the detail of the urllib module and HTTP error 403.
Table of Contents
Why Do We Use the Urllib Module?
The urlib module is a standard library module in Python that allows us to easily access and manipulate data on the web. It is a powerful tool when you are dealing with web data in Python.
Additionally, it is used for retrieving data, sending data, handling cookies, working with HTTP headers, and parsing URLs and data from the web.
The urllib package is often included with the Python installation, so it is usually optional to install it separately. However, if the urllib module is not present in your environment, we can install it with this command.
Command
pip install urllib
Furthermore, it’s worth noting that there are two versions of the urllib package: urllib2 and urllib3. Python 2 uses urllib2, while Python 3 uses urllib3, which has some additional cutting-edge features.
What Does the “urllib.error.HTTPError: HTTP Error 403: Forbidden” Mean?
The classes for exceptions raised by urllib.request are defined in urllib.error module. This module assists in triggering exceptions whenever a URL fetching problem occurs.
When an unusual HTTP error occurs, such as when an authentication request fails, the HTTP error exception is raised. It belongs to the URLError subclass. Errors like “404” (page not found), “403” (request forbidden), and “401” (authentication required) are common.
The 403 status indicates that although the server understands the request, it won’t process it. It is a frequent mistake while using web scraping. The server sends a 403 error if a user is recognized without authorization to access a resource. Now let’s understand “urllib.error.httperror:HTTP error 403:forbidden” with the help of a simple example:
Code
# Example of HTTP Error 403
# first of all, import urllib.request module
import urllib.request
# it returns HTTPResponse object
my_url_request = urllib.request.urlopen('https://www.google.com/search?q=urllib+python')
# use the read() function to read the data
print(my_url_request.read())
Output
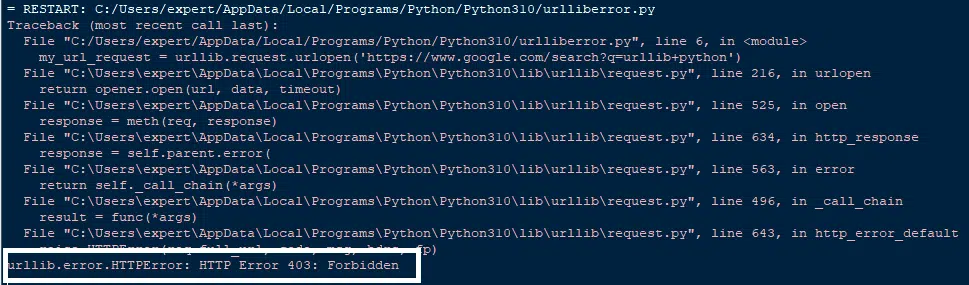
Reasons for the “urllib.error.HTTPError: HTTP Error 403: Forbidden” Error
Following are reasons that most of the time, web scrapers face “urllib.error.HTTPError: HTTP Error 403: Forbidden” error:
- This error results from mod security identifying and disabling the urllib scraping bot.
- Mostly we face this HTTP error due to not using the Session object of the request module.
- We get the “urllib.error. HTTPError: Forbidden HTTP Error 403” error when the server receives our request and decides not to authorize or process it. We need to look at an important file called robots.txt to figure out why the website we are visiting is not processing our request. If robots.txt is not checked, an HTTP error will occur.
4 Fixes for the “urllib.error.HTTPError: HTTP Error 403: Forbidden” Error
Following are the methods through which we can quickly get rid of this HTTP error.
Method 1: Providing User Information with the Help of User-Agent
A Python module called user agents makes it simple to recognize/detect mobile phones, tablets, and their capabilities by parsing (browser/HTTP) user agent strings. The objective is to accurately determine whether the user agent is running on a PC, tablet, or mobile device.
We need to include a user agent in the code in order to fix HTTP errors. By doing this, we can safely scrape the page without running into errors or being blocked.
The user-agent Mozilla/5.0 has been assigned to a new parameter named headers in the example below. The user-agent string provides the web server with information about the user’s computer, operating system, and browser. By doing this, the site won’t be able to block the bot.
For instance, the user agent string informs the server that your computer runs Windows OS and the Mozilla browser. The information is then sent in accordance with the server.
Now let’s understand user-agent with the help of a simple example:
Code
# User agent example
from urllib import request
from urllib.request import Request, urlopen
# store website address in a variable
website_url = "https://www.google.com"
# Providing user agent information
mysite_request = Request(website_url, headers={"User-Agent": "Mozilla/5.0"})
# Open URL
webpage_content = urlopen(mysite_request).read()
# print content on screen
print(webpage_content[:200])
Output
b' <!doctype html><html itemscope="" itemtype=" http://schema.org/WebPage" lang=" en"><head><meta content= "Search the world \'s information, including webpages, images, videos and more. Google has many speci'
Method 2: Using Session Object
Even using user-agent occasionally won’t stop the urllib.error.httperror: HTTP error 403: forbidden. We can use the Session object of the request module to fix this error. The website may use cookies as an anti-scraping measure. The website you’re scrapping may be set and asking for cookies to be echoed back in order to prevent scraping.
Cookies and the session object work together, so you can store some parameters by using a session object. Additionally, it uses urllib’s connection pooling and retains cookies across all requests from the Session object.
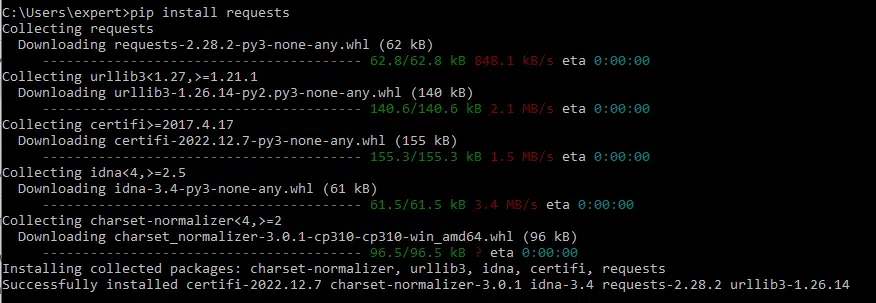
To use the session object, we have to install the requests module, so you have to execute the following command to install the requests package:
Code
pip install requests
Output
Now let’s understand session object with the help of a simple example:
Code
# import seed and requests module
from random import seed
import requests
Website_url = "https://www.google.com"
# create a session object
s_object = requests.Session()
# make a get request and store it in variable
r = s_object.get(Website_url, headers={"User-Agent": "Mozilla/5.0"})
# print response on the screen
print(r)
Output
<Response [200]>
Method 3: Check Robots.txt File
Examining and parsing the site’s robots.txt file is essential when scraping webpages and determining how effectively a site is set up for crawling. The directives and parameters included in this file tell bots, spiders, and crawlers what they can and cannot read; robots.txt must be kept at the document root of every web server.
When scraping a website, you should always check the robots.txt file and follow through with any instructions given there. We can use the syntax below to check the robots.txt file on any website.
Syntax
https://WebsiteName/robots.txt
For instance, by entering the URL, you may examine the robots.txt files on Google and YouTube.
https://www.google.com/robots.txt
https://www.youtube.com/robots.txt
Output
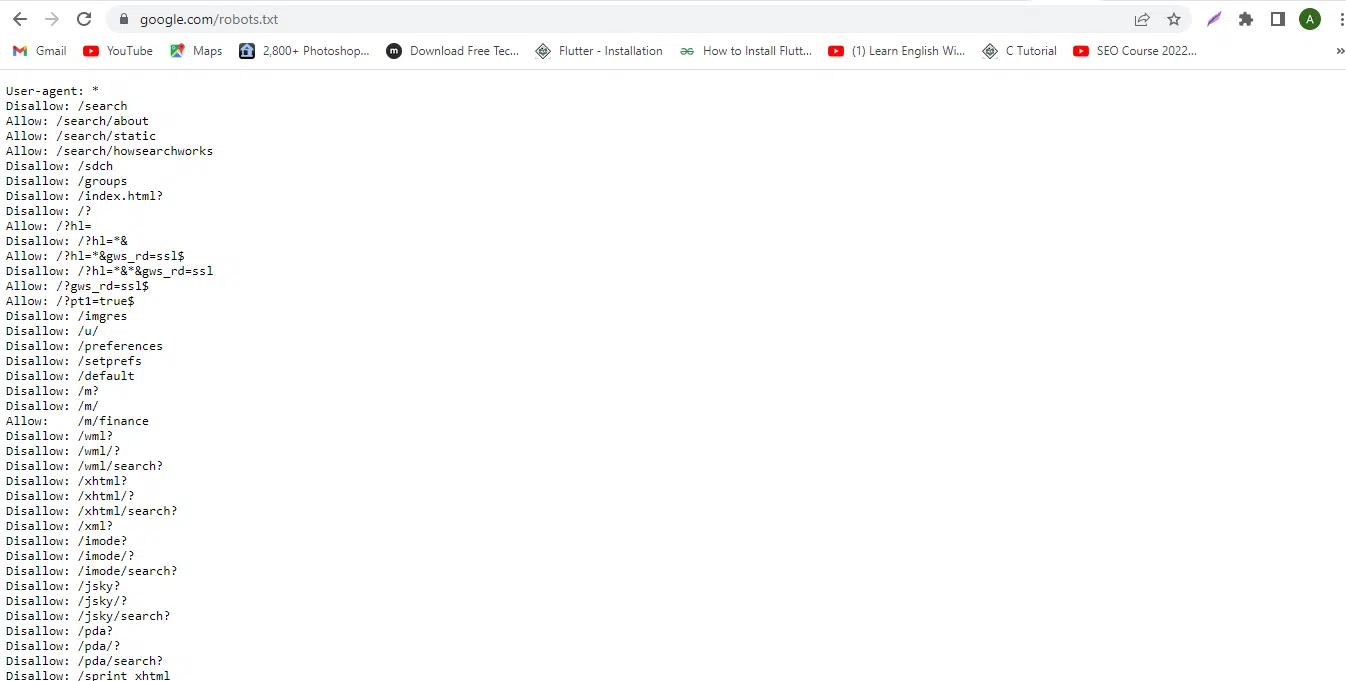
There are numerous Disallow tags to be seen. This Disallow tag displays the section of the website that is inaccessible. Any request to those places will not be fulfilled and is therefore forbidden. For instance, even with the urllib module, http://google.com/search is not allowed for any external requests.
Method 4: Use the Try Except Method
We can handle Exceptions with the try-except statement. The execution of a program could result in exceptions. Exceptions are mistakes that occur while the program is running. Python will immediately stop if it encounters issues such as syntax errors (syntax faults). The end user and developer both suffer from a sudden exit.
You can effectively address the issue using a try-except statement rather than an emergency stop. If you don’t handle exceptions correctly, an emergency suspension of the program will occur.
The general syntax of the try-except block is:
try:
# Write code that may generate errors here.
except:
# Execute this block if the code in try generate an error
Now let’s understand how try-except block handle “urllib.error.HTTPError: HTTP Error 403: Forbidden”:
Code
# import request urlopn and error
from urllib.request import Request, urlopen
from urllib.error import HTTPError
# url of website
myurl = "https://www.google.com/search?q=urllib+python"
# enter code between try block which may cause the error
try:
site_req = Request(myurl)
s_content = urlopen(site_req).read()
print(s_content[:500])
# exception block to handle errors and terminate the program properly
except HTTPError as exp:
print("HTTPError occured...")
print(exp)
Output
HTTPError occured...
HTTP Error 403: Forbidden
Conclusion
To conclude the article, we’ve discussed the reasons for this error, including disabling the urllib scraping bot, not using the Session object, and not checking the robots.txt file.
We also provided solutions to resolve the “urllib.error.HTTPError: HTTP Error 403: Forbidden”, including providing the user information with the help of User-Agent and using the Session object of the request module. By using these methods, web scrapers can easily resolve the “urllib.error.HTTPError: HTTP Error 403: Forbidden” error and continue their web scraping activities without being blocked.
Share this article with your fellow coders if you found it beneficial, and let us know in the comments below ⬇️.
Happy Coding! 🥳